Voici un livre paru en au milieu de l’année 2023 que j’ai trouvé pertinent et enrichissant. Pour peu que vous ayez eu des cours d’intelligence économique lors de votre cursus universitaire qui prédisaient avec l’avènement d’Internet et des technologies de l’information un nouveau type de guerre, ce livre en détaille tous les aspects et a le mérite de vous faire perdre vos illusions et notre idéalisme quant aux réseaux sociaux.
Derrière chaque invention révolutionnaire, il y’a toujours une bonne et une mauvaise utilisation, Internet n’échappe pas à la règle et sa déclinaison le web non plus.
S’il permet l’accès gratuit à la connaissance et représente un véritable enjeu d’égalité des chances David Colon chercheur à Sciences Politiques et membre d’un groupement de recherches au sein du CNRS documente avec une grande précision la manière dont depuis 1990 les états se sont appropriés cet outil pour servir leurs propagandes et gagner les guerres d’opinion. Inventé par les américains qui en ont fait les premier un terrain de jeu, nous allons voir à travers la lecture du livre que les régimes autoritaires ne sont pas en reste.
En effet, si dans un premier temps les russes et les chinois ont cherché à cloisonner cet espace de liberté afin de garder le contrôle sur leur population et éviter les révolutions populaires, aujourd’hui elles sont en passe de gagner leur pari de gangréner les démocraties occidentales par des campagnes hallucinantes de désinformation :
Fermes de trolls, botnets, faux comptes, financements publics ou privés d’agences de communication, le but est de déstabiliser, influencer en s’immisçant dans nos esprits afin de nous diviser, de nous affaiblir dans notre liberté d’agir, de réfléchir et même d’élire nos représentants en s’ingérant jusque dans le processus électoral.
La lecture de ce livre vous permettra de remettre en perspective votre propre utilisation de ce média et surtout des réseaux à utiliser avec précaution et parcimonie. Il est bon de toujours développer votre esprit critique quant aux informations que vous lisez et les images que vous voyez encore plus en 2025 avec les IA génératives qu’il est facile d’utiliser pour inonder l’espace informationnel et véhiculer des mensonges dans le but de servir des intérêts peu louables.
Lors de mon premier stage en entreprise, je me rappelle d’un mot de ma tutrice qui m’avait fait part de l’importance de faire une veille hebdomadaire pour se tenir informé du monde en constante évolution dans lequel nous vivons.
Peu de temps après je découvrais par curiosité un service de Google qui était d’une puissance sans égale j’ai nommé Google Reader fermée en 2013 capable d’indexer tout le contenu d’un site web simplement en entrant l’URL du site d’information en question. Ce service était basé sur la fameuse technologie Really Simple Syndication ou RSS.
La technologie RSS est elle même basée sur le langage XML qui sont tous les deux issues du W3C l’association créée par Tim Berners Lee, l’inventeur du protocole Hypertexte et du Web dont j’ai déjà parlé dans cet article.
Le langage XML pour Extensible Markup Language est un langage à balise tout comme le HTML sauf qu’elle est sous forme de nœuds c’est à dire des balises imbriquées les unes dans les autres et que le nom de chaque balise peut-être personnalisé à sa guise pour structurer les données.
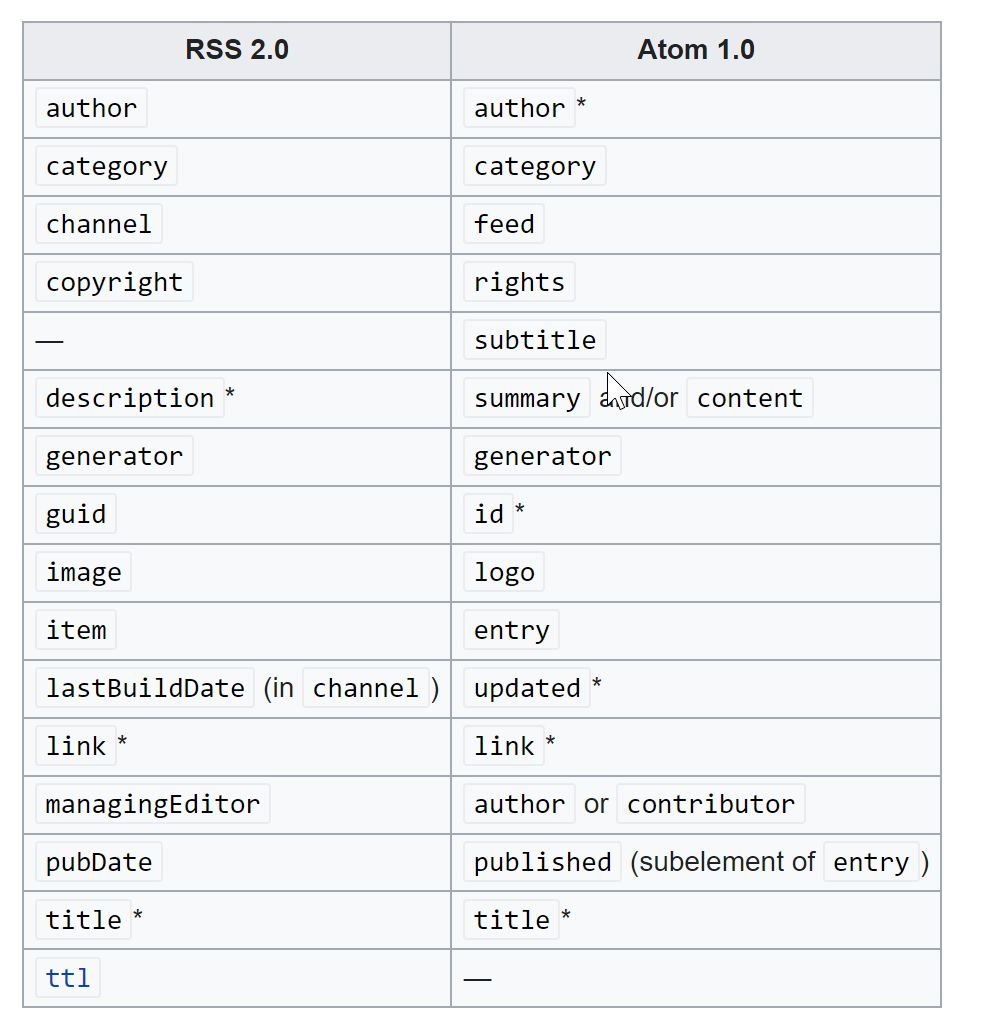
Il existe plusieurs versions de la technologie RSS : Le RSS 1, le RSS 2 (le plus utilisé aujourd’hui) et une technologie plus récente standardisé par l’IETF (encore eux) ATOM 1.
Dans RSS des balises XML ont été définies.
La différence entre RSS 2 et ATOM est négligeable, les balises qui structurent la page XML sont très similaires.
@Wikipedia
Comment cela marche RSS ? Pour faire simple, un flux RSS est une page de contenu structurée via le langage XML véhiculée par le protocole HTTP dont on a déjà parlé.
Ce contenu est très facilement indexé par un agrégateur de news dont le code permet : récupération , mise en forme et organisation de tous les flux de vos sites préférés pour faire une veille rapide et efficace. Nous reviendrons aux différents agrégateurs à la fin de l’article.
Sachez qu’il existe un autre langage que XML développé il y a peu basé sur la technologie serveur Javascript Object Notation j’ai nommé JSON (Ryan Dahl) baptisée JSON Feed.
Quels sont les agrégateurs de sites ? Je n’en citerai que deux :
Le meilleur pour une technologie propriétaire et fermée qui compte le plus d’utilisateurs est baptisé Feedly. Il est utilisé par plus de 18 millions de personnes.
Il est très efficace, ergonomique, simple d’utilisation, complet et puissant. Je l’utilise sur mon mobile et il vous suffit d’une adresse de courrier électronique pour pouvoir l’utiliser gratuitement même si l’ajout récent de nouvelles fonctionnalités liées à l’IA (Ex : Construction de flux à partir d’un lien) nécessite la version pro ou business qui sont payantes.
Si vous êtes sur Linux, le meilleur est certainement RSS Guard.
Il y’a de cela une bonne dizaine d’années j’avais pu ajouter les thèses pluridisciplinaires ouvertes de l’INRIA : l’institut national de recherche en informatique et en automatisation qui est un corps d’état public de recherche.
Les sites wordpress génèrent tous un flux RSS dont le XML se trouve juste derrière la racine du site en rajoutant /feed/
Ex : https://sciencetic.fr/feed/
C’est informatif si vous souhaitez juste consulter le code XML mais des agrégateurs comme Feedly le savent et vous pouvez directement entrer l’adresse du site dans l’agrégateur ou même chercher des flux référencés par domaine via des hashtags #
Pour détecter ou sont loggés les flux RSS d’un autre site d’information culturelles ou scientifiques par exemple celui du point, voici un petit tutoriel :
1 / Rendez-vous sur lepoint.fr qui est la page de base en somme la page des actualités :
2/ Ouvrez la console développeur de votre navigateur favori avec F12,
3/ Sélectionnez « Mise en Page » et faites une recherche avec « Ctrl + F » : tapez rss
4/ Après href pour hypertext référence vous trouverez l’URL à rajouter derrière lepoint.fr/ pour accéder au code XML du flux RSS : Dans l’exemple https://lepoint.fr/rss.xml
Site du Point
Ajoutez cette URL https://lepoint.fr/rss.xml à votre agrégateur et le tour est joué vous avez désormais accès à un flux qui récapitule toutes les dernières informations des actualités du site du Point :
Version vidéo du tutoriel :
Si ce n’est pas clair voici une version vidéo du tutoriel notamment pour les derniers dépôts des archives ouvertes pluridisciplinaires de l’INRIA :
Institut National de Recherche en Informatique et Automatisation
Voilà je ne veux pas faire trop long et j’espère que cela va vous permettre de découvrir l’univers des agrégateurs de news que ce soit sur mobile ou sur ordinateur et la puissance de cette technologie d’information surtout sur un téléphone portable !
Pour finir, j’insisterai sur un dernier point : lorsque vous faites votre veille qu’elle soit informative ou scientifique, n’oubliez pas de toujours faire appel à votre analyse critique. Prendre du recul surtout à l’époque de la guerre d’information, des complotistes, des articles écrits par des algorithmes et des fake news.
Ainsi, lorsque quelque chose vous paraît incongru, cherchez l’auteur, et croisez les sources !
Est-ce que Tim Berners-Lee avait conscience lorsqu’il inventa le web en 1989 de la portée de son invention dans la démocratisation du savoir ? Je veux parler bien sûr du protocole de transfert hyper texte et de son langage référent le Hyper texte Markup Language.
Si il avait pour but de révolutionner le cheminement de l’information lors de son passage au Centre Européen de recherche nucléaire il y’a un élément fondamentale qu’il n’avait peut-être pas prévu, ou du moins dont il a sûrement sous-estimé la portée : cliquer sur un lien ou un mot pour en connaître le sens…
Je veux parler de la fameuse balise « Anchor » ou ancre du langage HTML qui permet de transformer un bloc, une image ou un mot en un « hyperlien » pour faire référence à une autre page ou à une page de définition. Sur ce modèle a été bâti le succès de Wikipedia et toutes les encyclopédies en ligne ou autres dictionnaires numériques qui sont des véritables accélérateurs de mémorisation.
Il a rendu accessible ce qui était réservé à une élite lors de processus de discussions ou deux interlocuteurs rebondissent sur un mot ou une idée pour se l’approprier ou la définir.
Il n’est pas étonnant que le vieux monde ou les régimes totalitaires aient été réfractaire à l’avènement du web et des technologies de l’information quand chaque étudiant ou autodidacte avait accès à des trésors de connaissances.
Si on en a la volonté tout est à notre portée pour pouvoir apprendre et s’exercer : en quelques clics, prises de notes, sites spécialisés pour peu que l’on connaisse les bases du domaine que l’on souhaite approfondir : mathématiques, biologie moléculaire.
Certes, cela ne remplacera jamais les livres et leurs approche pédagogique mais avouez que nos bons vieux Larousse ont pris un vrai coup de vieux lorsque nous devons passer d’une page à l’autre rangées par ordre alphabétique pour approfondir un ensemble de définition…
Une initiative intéressante dont je souhaitais parler ici est celle du CNRS avec son trésor de la langue française qui a été mis en ligne vers 2008 que j’ai découvert pendant mes études accessibles sur cnrtl.fr et dont chaque mot contrairement à wikipedia est un hyperlien.
Sur un simple clic gauche un menu s’ouvre et vous avez accès à la lexicographie, la morphologie ou l’étymologie complète du mot comme le montre cette image de la définition du terme « primitive »
Exemple du mot « primitif » sur le centre de ressources textuelles et lexicales
Comme dans un dictionnaire vous disposez de toutes les acceptions du mot en question par discipline le tout surligné peut-être pour stimuler votre mémoire visuelle.
Le pouvoir de la connaissance est entre nos mains…
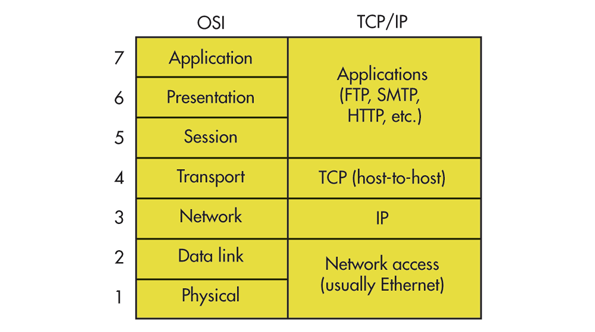
Après avoir abordé le modèle OSI et ses différentes couches, intéressons au nous au modèle TCP/IP. (Protocole de contrôle de transmission) (Protocole Internet).
Composé de deux protocoles un pour le transport et un pour l’adressage, le modèle tcp est plus ancien et plus simple que le modèle OSI, il se divise en 4 couches.
Le schéma suivant présente les correspondances entre les couches du modèle OSI et du modèle TCP :
OSI Model vs TCP Model @Electronic Design
Pour bien comprendre, les protocoles de plus haut niveau tels que HTTP se basent sur le protocole TCP pour fonctionner. Il existe un autre protocole de transport moins fiable et plus léger que nous verrons plus tard : UDP.
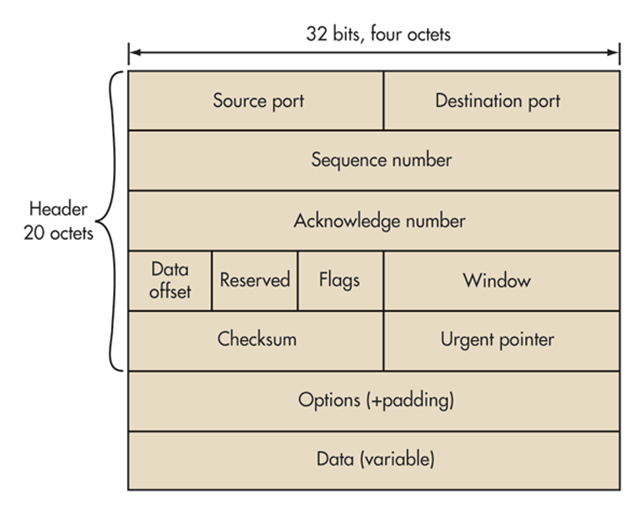
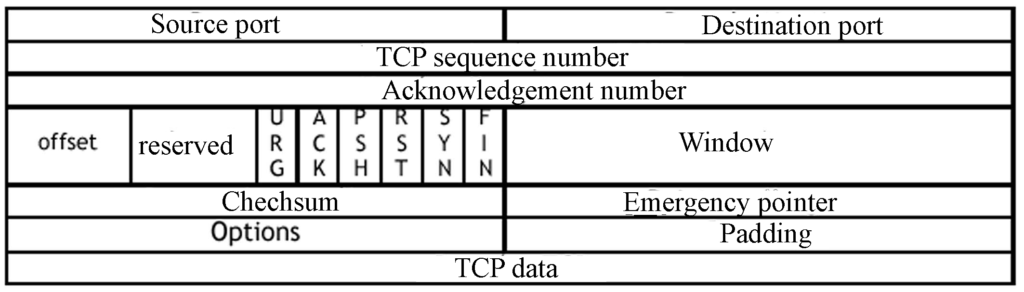
Le protocole TCP s’encapsule et se désencapsule (tout dépend si l’ordinateur est émetteur ou récepteur) vers la couche suivante d’un en-tête qui contient des informations cruciales telles que la source et la destination.
Les cinq premières couches totalisent 160 bits. Chaque couche est donc de 32 bits soit 4 octets, on trouve 5 couches dont le numéro de séquence, le numéro d’acquittement, une autre couche pour la taille de l’en-tête, une réservation et les flags qui sont des bits de contrôle ou signalisation qui représentent 4 bits chacune. Il est très important de souligner le protocole TCP ouvre des ports logiques sur l’ordinateur. Ces ports sont complémentaires de l’adresse IP et tous ensemble : 192.168.1.100:41340 cela représente ce que l’on appelle un socket.
Attachons nous à décrire le protocole TCP en détail en analysant son en-tête :
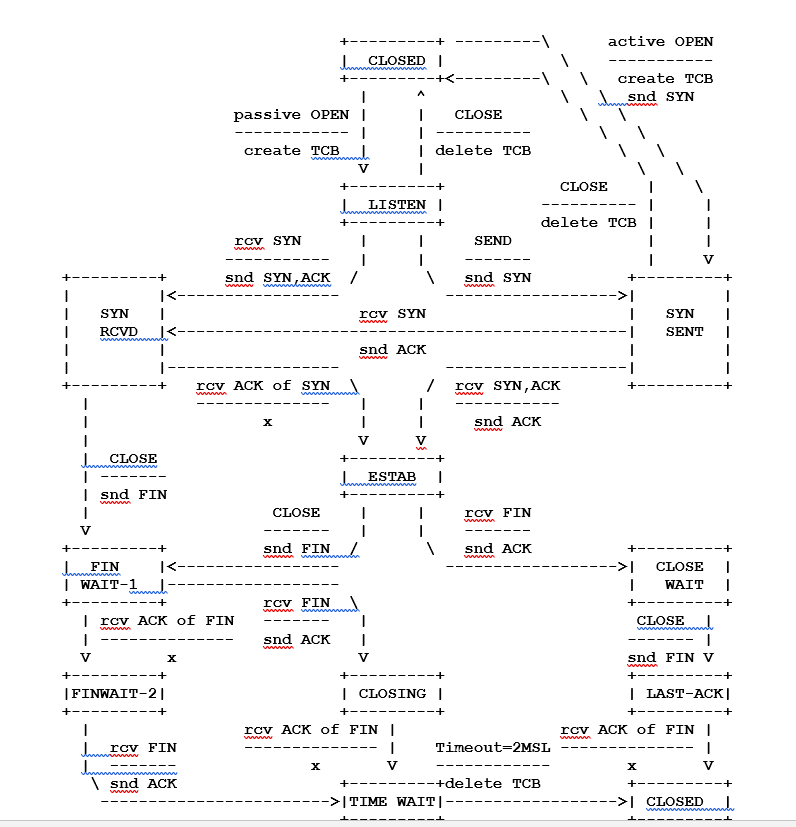
Mais qu’est ce qui se passe quand vous utilisez concrètement le protocole TCP ? Je vous invite à consulter les RFC (Request for comments) de l’IETF (Internet Engineering Task Force) :
RFC 793 @IETF
Ce schéma est assez difficile à lire mais il a le mérite d’être très fidèle à ce qui se produit quand deux ordinateurs communiquent via TCP.
SYN, ACK, FIN sont donc les flags, bits de contrôle ou signalisations comme les panneaux du code de la route que j’ai évoqué qui sont les indicateurs clés du fonctionnement du protocole.
Les encadrés sont les différents états de TCP que vous pouvez retrouver en tapant encore une fois « netstat » via une invite de commande sur votre ordinateur.
Il existe encore d’autres bits de contrôles ou signalisation tels que PSH pour push, RST pour reset, URG pour urgent, CWR pour la congestion réseau, la congestion réseau est étudiée via une RFC à elle seule (3168).
Le protocole IP a également son propre en-tête :
Qu’est-ce qu’une adresse IP ?
Une IP par exemple 192.168.100.254 interprété ici dans sa forme décimale mesure 32 bits soit 4 octets :
Si vous savez lire le binaire encodé sur un octet cela fait :
192 = 11000000
168 = 10101000
L’en-tête se lit de haut (départ) en bas (fin) en fonction si vous êtes l’émetteur ou le récepteur voir modèle OSI.
1ère ligne :
Version : 4 bits | Donne des informations sur le type d’en-tête, savoir si vous êtes V4 ou V6 par exemple. Le format présenté est celui de la V4.
Longueur de l’en tête : 4 bits | code la longueur de l’en-tête, l’unité étant un mot de 32 bits, il indique le commencement de la donnée.
Type de service : 8 bits | donne une indication sur la qualité de service demandée cependant cela reste un paramètre abstrait. Cette option est utilisée pour guider le choix de paramètres quand un datagramme transite a partir d’un réseau spécifique. Certains réseaux offrent un mécanisme de priorité. Certains types de trafic vont êtres traités préférablement plutôt qu’un autre. Le choix principal obéit à trois contraintes : un court délai, un débit d’erreur bas, ou un gros volume de sortie.
Taille totale : 16 bits | Le champ taille totale est un la longueur du message de données complet ou datagramme incluant l’en-tête et la data mesurées en octets. Ce champs peut seulement coder un datagramme de 65,535 octets. Une telle longueur serait impossible à gérer pour la majorité des réseaux. L’hôte acceptera un datagramme d’une longueur d’environ 576 octets que ce soit un datagramme ou un fragment. Il est par ailleurs recommandé de ne pas envoyer de datagramme de plus de 576 bits à moins qu’ils soient sure que la destination est capable de les accepter.
2ème ligne :
Identification : 16 bits | Une valeur d’identification, allouée par l’émetteur pour identifier les fragments d’un seul datagramme ou message.
Flags : 3 bits | Ce sont des bits de signalisations ou contrôle : le bit 0 est réservé il doit rester à 0. Le bit 1 pour (DF) (Don’t fragment) à 0 indique que la fragmentation est possible, à 1 il indique que le bit est non-fractionnable donc il sera détruit. Le bit 2 pour (MF) More fragments : si il est à 0 c’est le dernier fragment, si il est à 1 on a un fragment intermédiaire.
Fragment offset : 13 bits | Ce champ indique l’écart du premier bit de fragment en lien avec tout le message. Cette position relative est mesuré en 64 bits soit 8 octets. L’écart du premier fragment est égal à 0.
3ème ligne :
Time to live : TTL : 8 bits | Ce champ limite le temps qu’un datagramme reste dans le réseau, si ce champ est égal à zéro, le message doit être détruit. Ce champ est modifié durant le traitement de l’en tête Internet. Chaque module Internet (routeur) doit retourner au moins une unité une fois de ce champ durant la transmission d’un paquet même si la prise en charge de ce message par le module dure moins d’une second. Ce temps de vie doit être vue comme la durée de temps maximum pour qu’un datagramme existe . Ce mécanisme existe par nécessité de détruire n’importe quel message qui n’a pas été correctement transmis au réseau.
Protocol :8 bits | Ce champ indique quelle version du niveau supérieur de protocole est utilisée dans la section de donnée du message Internet. Les différentes valeurs allouées pour des protocoles variés sont listés dans les nombres assignés de la RFC 1060.
CRC(contrôle de redondance cyclique) 16 bits | Somme de redondance cyclique calculée uniquement dans l’en-tête. Certain des champs de l’en-tête sont modifiés durant leur transit a travers le réseau, cette somme de contrôle doit être recalculée et vérifié à chaque endroit du réseau ou l’en-tête est réinterprété.
Adresse Source : 32 bits : Adresse IP
Adresse de Destination : 32 bits : Adresse IP
La notation CIDR
Toute adresse IP est masquée par un masque de sous réseau, lorsque l’on lit 192.168.100.0/24, cela veut dire que comme l’adresse est codée sur 32 bits que 24 bits sont masqués. En fait mon masque compte 24 bits en binaire ce qui veut dire que mon masque est 255.255.255.0 soit 11111111.11111111.11111111.00000000
La partie /24 correspond à la notation CIDR. Si 24 bits sont masqués, les 8 derniers sont disponibles mais les autres constituent ce qu’on appelle le net id ou l’adresse réseau.
J’obtiens donc une adresse réseau en 192.168.100.X avec 8 bits soit 2^8 hôtes disponibles. Dans ce plan d’adressage, je ne pourrai avoir que 255 machines qui communiquent entre elles : le dernier octet mis en gras.
Mon sous réseau correspond a 192.168.100.X et me donne un nombre d’hôtes disponibles soit 255 ce qui correspond au nombre d’hôtes ou machines qui pourront avoir une adresse dans ce plan d’adressage. En effet je peux avoir une machine en 192.168.100.1 ou en 192.168.100.2.
Ces deux machines étant sur le réseau 192.168.100.X elles pourront communiquer entre elles.
Une métaphore simple pour comprendre : l’adresse réseau ou net id est le nom de la rue, le reste de l’IP ou host id est le numéro de la rue et le nom du bâtiment, et les ports sont les étages et les numéros d’appartements.
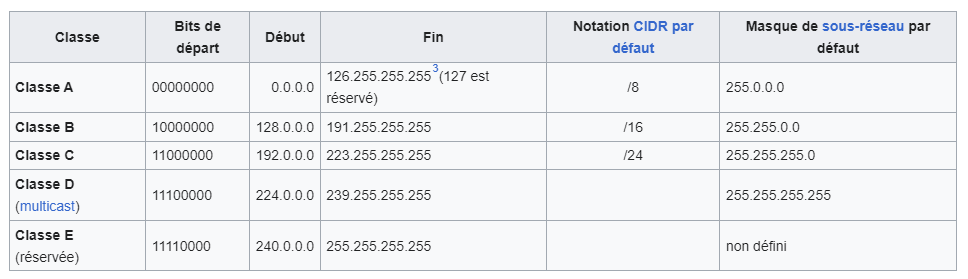
Les classes d’adresses :
Il existe cinq classes d’adresses IP toutes définies par le premier octet de l’adresse :
Une adresse IP de classe A dispose d’une partie net id comportant uniquement un seul octet.
Une adresse IP de classe B dispose d’une partie net id comportant deux octets.
Une adresse IP de classe C dispose d’une partie net id comportant trois octets.
Les adresses IP de classes D et E correspondent à des adresses IP particulières.
J’ai étudié le modèle OSI par curiosité au cours de mon premier cursus universitaire. Il représente un guide efficace pour la compréhension des communications électroniques entre deux ordinateurs notamment pour le binôme client/serveur. Ce modèle est vraiment pratique et vous le rencontrerez très certainement dès que vous souhaitez toucher au réseau.
Il divise la communication réseau en 7 couches : 3 couches physiques ou matérielles qu’on pourra appeler les couches basses et 4 couches hautes qu’on appellera les couches logicielles. Dans cet exemple pour comprendre le chemin que les données puis les bits (binary (0,1) digit) traversent. Imaginons un utilisateur sur son ordinateur qui navigue sur Internet on l’appellera l’émetteur : partez du haut à gauche de l’image puis descendez jusqu’aux impulsion s électriques représentés par des bits et le lien physique pour arriver jusqu’au serveur qu’on appellera récepteur. Ce schéma se reproduit et s’inverse en boucle chaque fois que les deux ordinateurs communiquent. L’émetteur devient récepteur et vice et versa.
Si ce modèle est aussi utilisé c’est parce que comme son nom l’indique il vulgarise le fait que les ordinateurs et Internet est un monde ouvert (OSI veut dire Open System Interconnexion) dans lequel chaque fois que vous que consulter votre site favoris vous vous connectez à un autre ordinateur pour peu qu’on vous laisse y accéder par une porte (PORT (65 535 sur un pc)) selon un protocole défini et codé.
Ces protocoles vous les retrouvez lorsque vous cliquez sur un lien (HTTP) (Protocole de Transfert HyperText) ou lorsque vous établissez la connexion avec l’ordinateur distant. Le modèle OSI permet à peu près de classer tous ces protocoles dans les différentes couches :
OSI MODEL
HTTP est donc un protocole très haut au niveau de la machine, plus on se rapproche des impulsions électriques et plus on est bas niveau. Pour le protocole TCP/IP qui a son propre modèle plus ancien, il est divisé lui même en deux protocoles : TCP, Protocole de contrôle de transmission et IP, Protocole Internet. Ils ont été conçus pour fonctionner ensemble, pour cette raison on les associe souvent.
Pourtant on retrouve le protocole IP sur la couche 3 (Réseau) et TCP sur la couche 4 (Transport). Chaque couche a son propre lexique, dans les 3 plus hautes on parlera de données, au niveau transport de segments, au niveau réseau de paquets , au niveau liaison de trames et au niveau physique de bits.
Si vous voulez avoir un aperçu qu’Internet est un monde ouvert ouvrez une interface de commande et tapez « netstat » vous aurez la liste des communications établies entre vous et le monde, Microsoft si vous êtes sur Windows, Google si vous êtes sur chrome.
Amusez vous a tracer les IP avec un « tracert » (traceroute) avec l’adresse IP pour voir tout le chemin que traversent les électrons jusqu’aux différents routeurs mis en place par les entreprises de télécommunications. Utilisez un logiciel comme Wireshark pour une analyse poussée de tout ce qui se passe au niveau réseau de votre machine. Investissez dans un pare-feu très configurable et lisible.